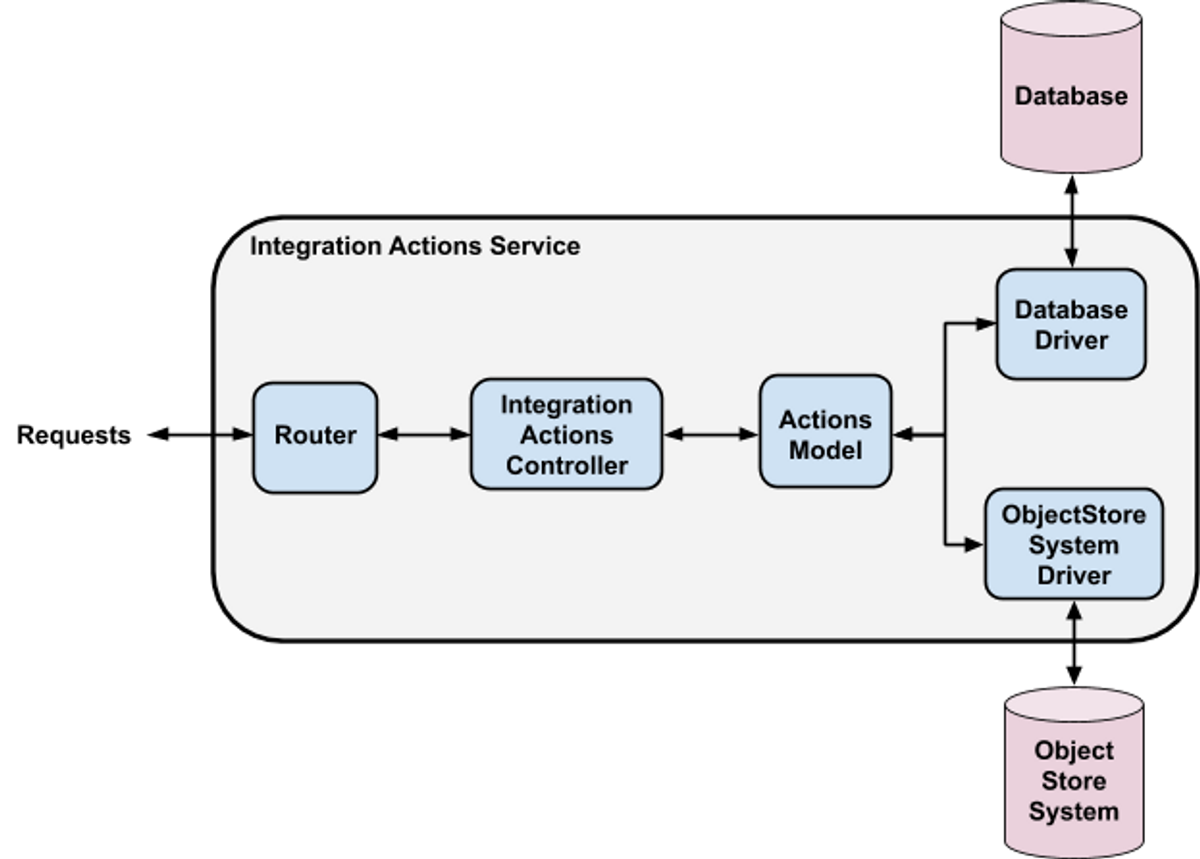
Apr 15, 2020 "Reducing Operational Noise by Diving into a Legacy System" legacy systemsengineering at pagerdutypagerduty legacy systems reduce operational noise